










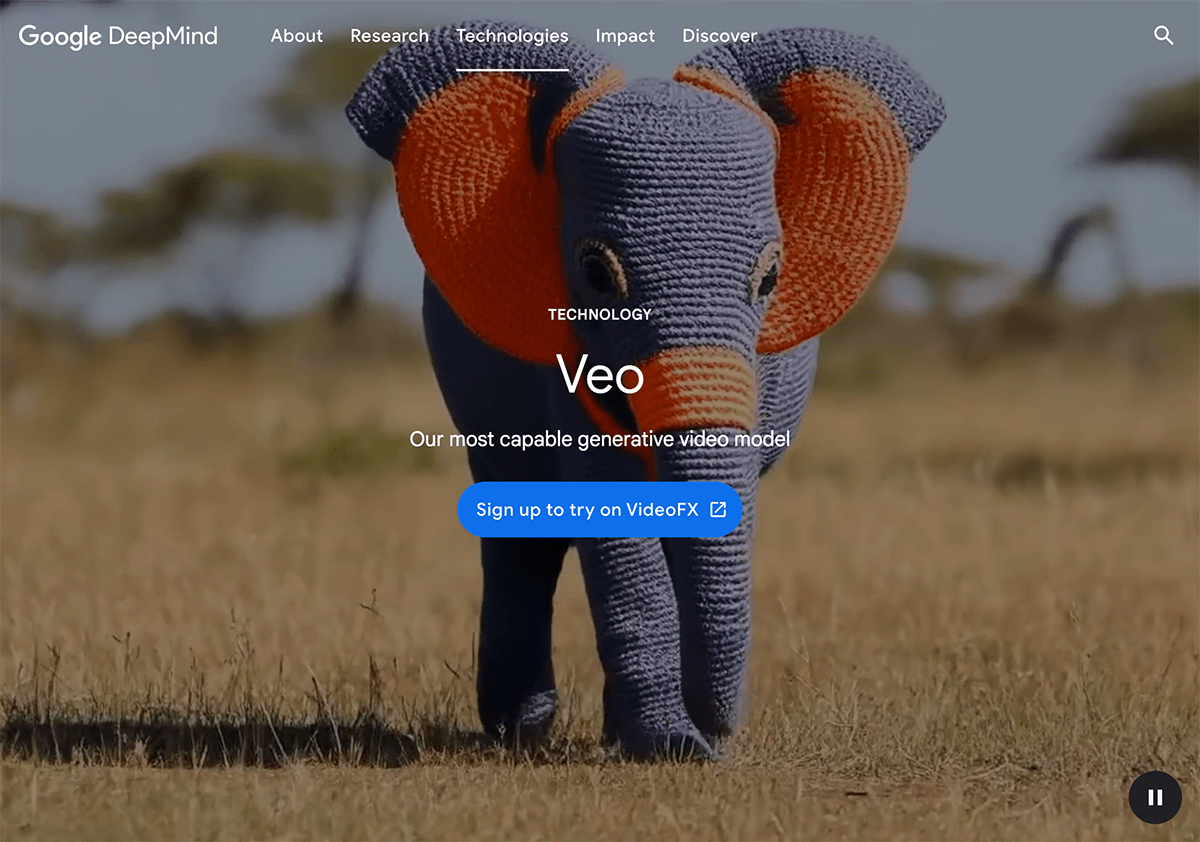
Veo 是什么
Veo 是 Google DeepMind 最新发布的一款 AI 文本到视频生成模型,是 DeepMind 迄今为止功能最强大最先进的视频生成模型,Veo 可以生成超过60秒的的高质量 1080p 分辨率的视频,从照相现实主义到超现实主义和动画,可以处理多种电影和视觉风格。Veo 能准确捕捉提示语的细微差别和语气,并提供前所未有的创意控制水平,Veo 能理解 “延时摄影 “或 “航拍风景 “等电影术语,而且 Veo 创建的镜头连贯一致,因此人物、动物和物体在整个镜头中的移动都非常逼真。

Veo 视频生成模型将有助于创建人人都能使用的视频制作工具。无论您是经验丰富的制片人、有抱负的创作者,还是希望分享知识的教育工作者,Veo 都能为您带来讲故事、教育等方面的新可能性。
Veo 的技术优势
✅ 更好地理解语言和视觉
为了产生连贯的场景,生成视频模型需要准确地解释文本提示,并将此信息与相关的视觉参考相结合。凭借对自然语言和视觉语义的先进理解,Veo可以生成紧跟提示的视频,它能准确地捕捉到一个短语的细微差别和语气,在复杂的场景中呈现出复杂的细节。
✅ 电影制作控制
当输入视频和编辑命令(比如在海岸线的航拍照片中添加皮划艇)时,Veo可以将该命令应用于初始视频,并创建一个新的编辑视频。此外,它还支持掩码编辑,当您向视频和文本提示添加掩码区域时,可以更改视频的特定区域。
✅ 支持图片生成视频
Veo 还可以生成带有图像作为输入和文本提示的视频。通过提供与文本提示相结合的参考图像,它约束Veo生成遵循图像样式和用户提示指令的视频。Veo 还可以制作视频片段,并将其扩展到60秒或更长时间。它既可以通过一个提示,也可以通过一系列提示来讲述一个故事。
✅ 跨视频帧的一致性
对于视频生成模型来说,保持视觉一致性是一个挑战。角色、对象甚至整个场景都可能在帧之间闪烁、跳跃或变形,从而破坏观看体验。Veo的尖端潜伏扩散变压器减少了这些不一致的外观,保持人物,物体和风格的位置,就像他们在现实生活中一样。
✅ 基于多年的视频生成研究
Veo 建立在多年生成视频模型工作的基础上,包括生成查询网络(GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet和Lumiere,以及我们的Transformer架构和Gemini。为了帮助 Veo 更准确地理解和遵循提示,我们还在其训练数据中的每个视频的标题中添加了更多细节。为了进一步提高性能,Veo 模型使用高质量的压缩视频技术,因此效率也更高。这些步骤提高了整体质量,减少了生成视频所需的时间。
✅ 负责任的设计
负责任地把像Veo这样的技术带到世界上是至关重要的。Veo制作的视频使用SynthID进行水印,SynthID是我们用于水印和识别人工智能生成内容的尖端工具,并通过安全过滤器和记忆检查过程,有助于减轻隐私、版权和偏见风险。
Veo 如何使用
在未来几周内,Veo 的部分功能将通过实 labs.google 的新实验工具 VideoFX 提供给选定的创作者,您现在就可以加入等待名单。
- 等待名单申请地址:http://labs.google/VideoFX
未来,我们还将把 Veo 的部分功能带到 YouTube 短片和其他产品中。
数据统计
本站AI工具导航提供的Veo来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由AI工具导航实际控制,在2024年5月15日 上午4:29收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,AI工具导航不承担任何责任。
类似工具















 京公网安备11010502052249号
京公网安备11010502052249号